
Static Image with Rotating Light
Portrait and Half-body Scenario
Full-body Scenario
Multi-person Scenario
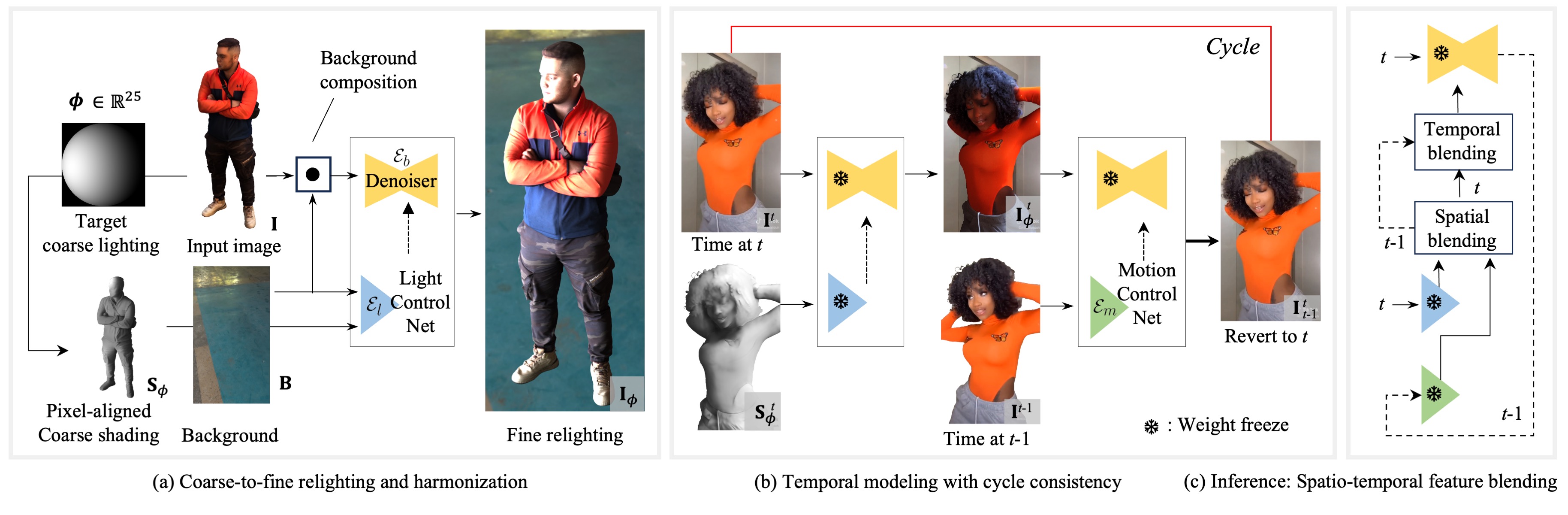
This paper introduces Comprehensive Relighting, the first all-in-one approach that can both control and harmonize the lighting from an image or video of humans with arbitrary body parts from any scene. Building such a generalizable model is extremely challenging due to the lack of dataset, restricting existing image-based relighting models to a specific scenario (e.g., face or static human). To address this challenge, we repurpose a pre-trained diffusion model as a general image prior and jointly model the human relighting and background harmonization in the coarse-to-fine framework. To further enhance the temporal coherence of the relighting, we introduce an unsupervised temporal lighting model that learns the lighting cycle consistency from many real-world videos without any ground truth. In inference time, our temporal lighting module is combined with the diffusion models through the spatio-temporal feature blending algorithms without extra training; and we apply a new guided refinement as a post-processing to preserve the high-frequency details from the input image. In the experiments, Comprehensive Relighting shows a strong generalizability and lighting temporal coherence, outperforming existing image-based human relighting and harmonization methods.

Video Relighting and Harmonization
We introduce a generalizable human relighting model that can control the lighting from an image or video of humans with arbitrary body parts, which are well-harmonized with a conditioning space as shown.
Portrait and Half-body Scenario
Full-body Scenario
Multi-person Scenario
@inproceedings{wang2025comprehensive,
title={Comprehensive Relighting: Generalizable and Consistent Monocular Human Relighting and Harmonization},
author={Wang, Junying and Liu, Jingyuan and Sun, Xin and Singh, Krishna Kumar and Shu, Zhixin and Zhang, He and Yang, Jimei and Zhao, Nanxuan and Wang, Tuanfeng Y and Chen, Simon S and others},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={380--390},
year={2025}
}